需求:对指定公众号的所有文章进行爬取。
参考资料
方案一
-
进入自己的公众号平台——>内容和互动——>草稿箱
-
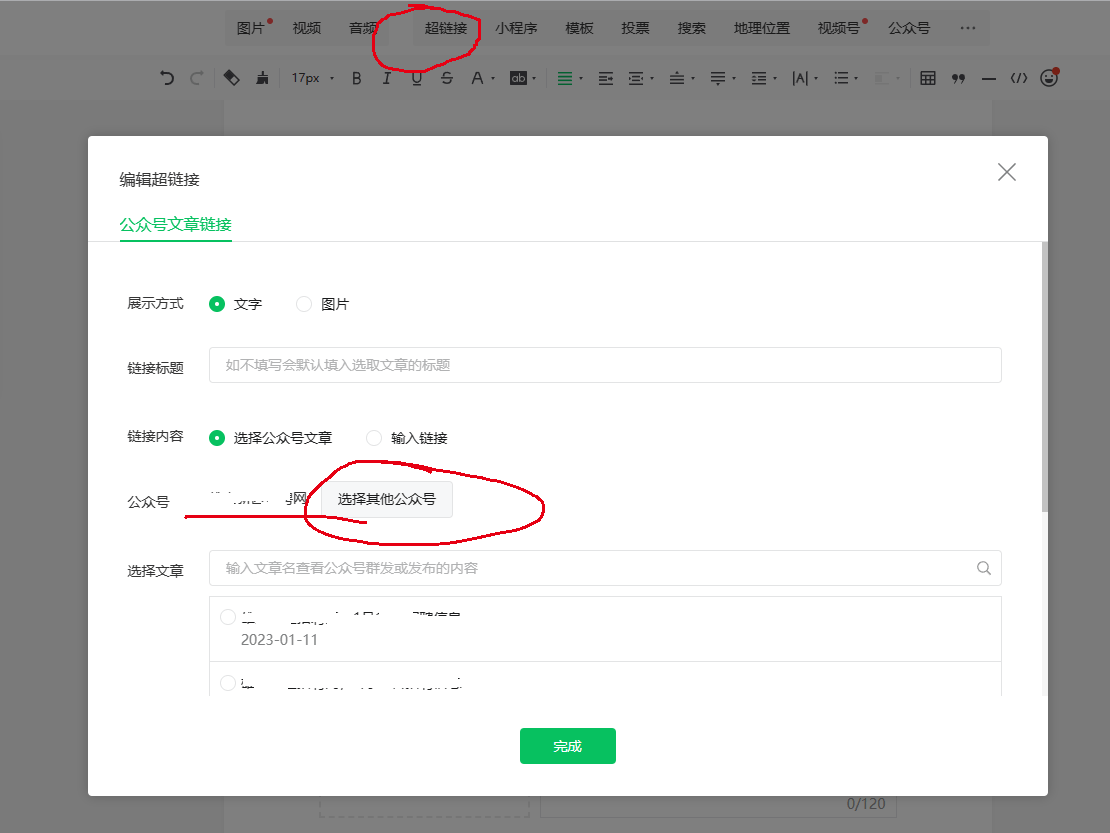
点击插入超链接——>公众号一行,选择其他公众号——>输入需要爬取的公众号并搜索
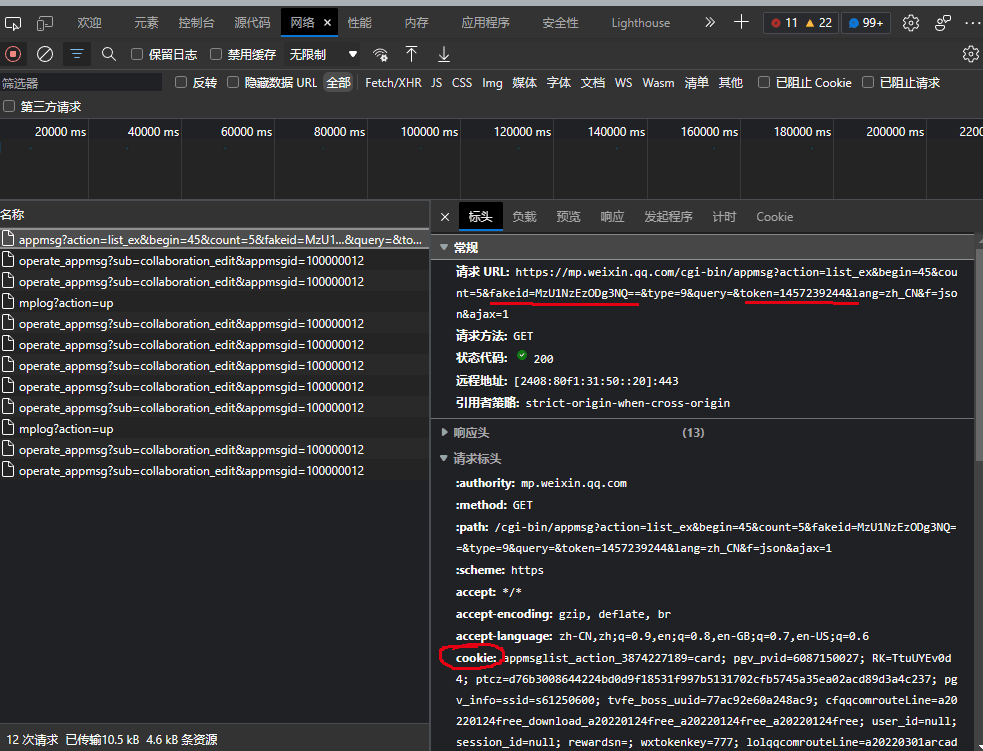
- F12,选择网络——>点击翻页,观察网络包——>在标头的请求url中获取fakeid和token和cookie
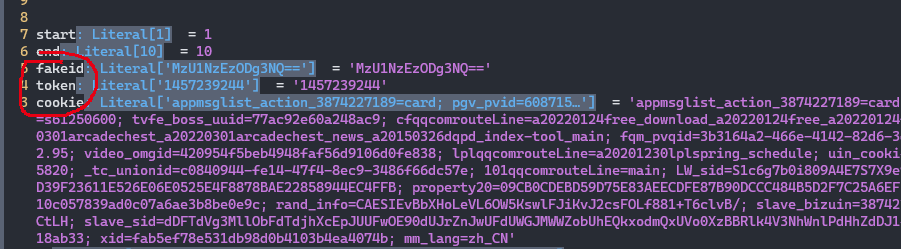
- 将上面获取的几项替换到代码中几项即可
code
# coding=utf-8
# -*- coding:uft-8 -*-
# 微信公众号
import requests
import datetime
from time import sleep
from lxml import etree
import pandas as pd
import re
import os
def validateTitle(tit):
reStr = r'[\/\\\:\*\?\"\<\>\|]'
newTitle = re.sub(reStr, '_', tit)
return newTitle
start = 1
end = 10
fakeid = 'xxx=='
token = 'xxx'
cookie = 'xxx'
ua = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36'
path = 'data'
if not os.path.exists(path):
os.makedirs(path)
# resLs = []
for i in range(start - 1, end + 1):
try:
i *= 5
url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin={}&count=5&fakeid={}&type=9&query=&token={}&lang=zh_CN&f=json&ajax=1'.format(i, fakeid, token)
headers = {
'authority': 'mp.weixin.qq.com',
'cookie': cookie,
'referer': 'https://mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit_v2&action=edit&isNew=1&type=10&token={}&lang=zh_CN'.format(token),
'user-agent': ua
}
res = requests.get(url=url, headers=headers).json()
for k in res['app_msg_list']:
timeStamp = k['update_time']
dateArray = datetime.datetime.fromtimestamp(timeStamp)
time = dateArray.strftime('%Y-%m-%d %H:%M:%S')
u = k['link']
hd = {
'User-Agent': ua,
'cookie': cookie
}
r = requests.get(url=u, headers=hd).content.decode('utf-8')
tree = etree.HTML(r)
title = tree.xpath('//h1/text()')[0].strip()
content = '\n'.join(tree.xpath('//div[@id="js_content"]//text()')).strip()
dic = {
'标题': title,
'时间': time,
'内容': content,
'链接': u
}
# resLs.append(dic)
print(dic)
open(f'data/{validateTitle(title)}.txt', 'a', encoding='utf-8').write(f'{title}\n{time}\n{content}')
sleep(5)
except Exception as e:
print(str(e))
sleep(5)
break
# df = pd.DataFrame(resLs)
# writer = pd.ExcelWriter('微信公众号.xlsx')
# df.to_excel(writer, encoding='utf-8', index=False)
# writer.save()