内存管理
编译(源程序模块)—》链接(目标模块)—》装入(装入模块)
1.链接和装入的策略,分为3种。在磁盘上,在内存中,在cpu执行时。
2.一个程序的运行,需要经过几道程序的运行。(编译器—链接器—装入内存(装入器)—内存分配(内存管理器))
编译器:将程序员写的源程序编译为目标模块
链接器:多个目标模块拼接,通过一定的策略形成可装入模块
装入器:将可装入模块,通过一定的策略装入内存
内存管理器:配合装入器,通过一定的策略完成对程序运行所需内存的分配
链接策略
- 静态链接:在装入内存之前,将各个目标模块链接起来。形成可装入模块(linux中就是链接.a静态库)
- 装入时动态链接:边装入边链接
- 运行时动态链接:执行时需要的时候才链接目标模块
装入策略(装入器loader)
- 绝对装入:程序的逻辑地址==进程的物理地址。缺点:编写的程序必须从指定位置开始,必须非常了解内存要求。常用于单道程序环境
- 可重定位装入:当程序被装入程序(loader)装入内存后根据实际可用物理地址来变更程序中全文的地址。此时能够运行躲到程序缺点:程序装入之后,不可动态修改程序中的地址
- 运行时动态装入:在指令被执行时,才动态修改地址。
内存分配策略(内存管理器mm_manager)
操作系统对内存的分配,大体上可以分为两个思路。1.分割内存,不分割装入模块(连续分区分配)。2.分割内存,并且分割程序(分页,分段,段页)
连续分区分配:
顾名思义,也就是程序作为一个整体装入内存中。而根据对内存的分割策略来看,有3种方式。
- 单一连续分配(整个内存分为内核区,和用户区。用户区只有一道程序)
- 静态分区分配(将用户区,划分固定大小的几个区域。开始可以存放多道程序,但可能有的程序很小,但是占据很大的区域,造成浪费)
- 动态分区分配(根据程序的大小来确定内存分区的大小)
- 动态重定位分区分配算法(在动态分区分配的基础上增加“紧凑”功能,减少内存的碎片,为了实现紧凑功能需要配合运行时动态装入的装入算法)
分页、分段、段页内存分配:
这些分配方式,不仅分割内存,还分割装入模块(进程)。可以看作数据结构中的链表。整个进程离散地分散到内存不同位置。不像连续分配,将装入模块整体装入。
-
分页
将程序和内存空间分割成多个大小一样的片段(页面),操作系统的内存管理模块通过为程序建立页表,然后MTU地址转换单元通过查询进程的页表,来实现程序地址的动态重定位。
当访问进程的某一条指令(比如:load 1,2500)2500是程序的逻辑地址,MTU首先计算得出该逻辑地址对应的程序分页中的页号,和页内偏移。然后通过在页表中查询到程序分页中的页号对应的物理块号,得到物理块号之后和前边的页内偏移相加,从而完成程序的逻辑地址到物理地址的转换。
-
分段
由于分页方法(固定大小的页面的缺点:不符合程序中指令和数据的排布,导致)的缺陷,提出一种分段内存分配的算法,将一个程序分割为不同段:代码段,数据段,堆段,栈段,bss段,作为一个查询单位。而将内存分割为与程序相同的段。这样只要通过段表查询到段基址,就能保证能够每一个段在内存中是连续分配的。

-
段页式
分页的好处是能够节省内存,分段的好处是程序友好,方便编程。为了结合两方面优势,将每一个程序段通过分页处理,然后通过段号找到页号,通过页号找到物理地址。
**内存模型到底是什么:**现在的编译器会将我们的程序进行分段处理,**c语言,c++中的内存模型,其实就是编译器所规定的一种逻辑上的程序组织方式,在内存中每一个段可能连续的一块(段式)来存储,也可能一个程序段分布在不同的物理内存(段页式)来存储,**然后在执行指令,进行地址转换时,操作系统根据实际内存分配方式,完成逻辑地址(每一个段的逻辑地址都是从0号开始的)到物理地址的转换,然后cpu访问物理地址来执行我们的程序。
unix系统标准&unix实现
unix标准
- iso c:该标准定义了c语言语法语义和c语言标准库,因为是所以unix都提供了c标准中的库函数,因此默认也就成了一种标准
- ieee posix:该标准的目的是提高应用程序在各种unix系统环境之间的可移植性
- SUS=single unix specification(单一unix规范):是posix的超集,在posix的基础上还规定了一些操作系统接口,扩展了posix的功能
unix实现
SVR4(system v release 4):System V 是 AT&T 的第一个商业UNIX版本(UNIX System III)的加强。传统上,System V 被看作是两种UNIX"风味"之一(另一个是 BSD)。然而,随着一些并不基于这两者代码的UNIX实现的出现,例如 Linux 和 QNX, 这一归纳不再准确,但不论如何,像POSIX这样的标准化努力一直在试图减少各种实现之间的不同。流行的SysV 衍生版本包括 Dell SVR4 和 Bull SVR4。当今广泛使用的 System V 版本是 SCO OpenServer,基于 System V Release 3,以及SUN Solaris 和 SCO UnixWare,都基于 System V Release 4。
BSD:
磁盘到文件系统
文件系统:是一种存储和组织计算机数据的方法,它使得对其访问和查找变得容易,文件系统使用文件和树形目录的抽象逻辑概念代替了硬盘和光盘等物理设备使用数据块的概念,用户使用文件系统来保存数据不必关心数据实际保存在硬盘(或者光盘)的地址为多少的数据块上,只需要记住这个文件的所属目录和文件名。
数据在硬盘上的存储和组织方式:

**连续块存储:**这是一种最简单的实现方式,管理便捷。但最大的问题是空洞问题,即使物理磁盘还有空余容量,也不能再写入文件了。常见于CD-ROM等预先明确数据大小的存储器
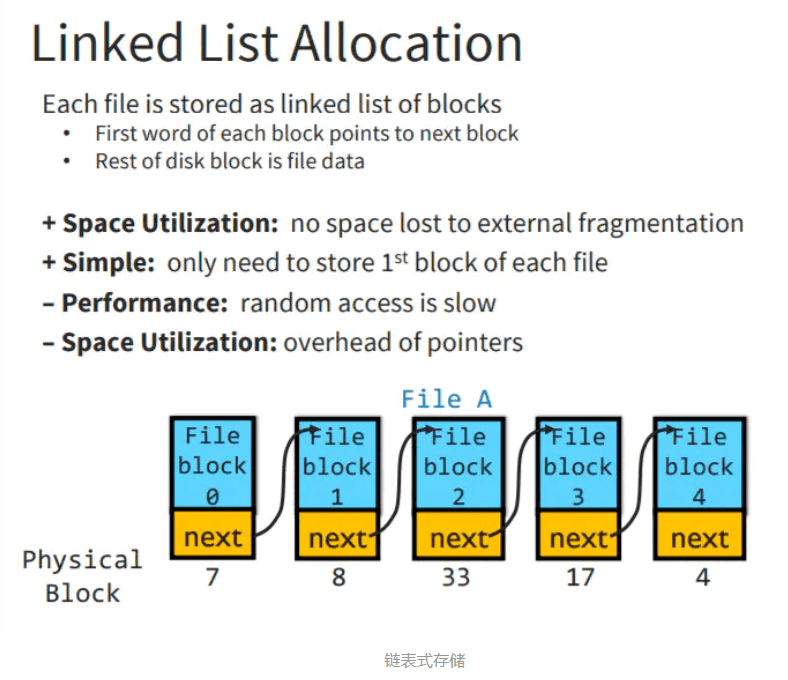
**链表式存储:**好处是不存在存储空洞且只需要记住第一个block的位置即可,缺点很明显:就是会造成大量的随机IO,而且读取完一个block才知道下一个block的位置,效率过低。为了改进这种效率问题,FAT诞生

**FAT:**链表式存储中,next指针是存储在每个block中的,而FAT把这些指针统一写在一个array中,这样获取一个文件的所有block位置就变得简单很多,效率也更高。但FAT也有一定的限制,比如FAT16只有65536个位置,FAT32虽然有更多的指针位,但是FAT表本身也占用了更大的内存。且FAT在读取某一文件中部时效率低,因为需要链表遍历。此外,FAT格式的文件系统不利于扩展文件的metadata。
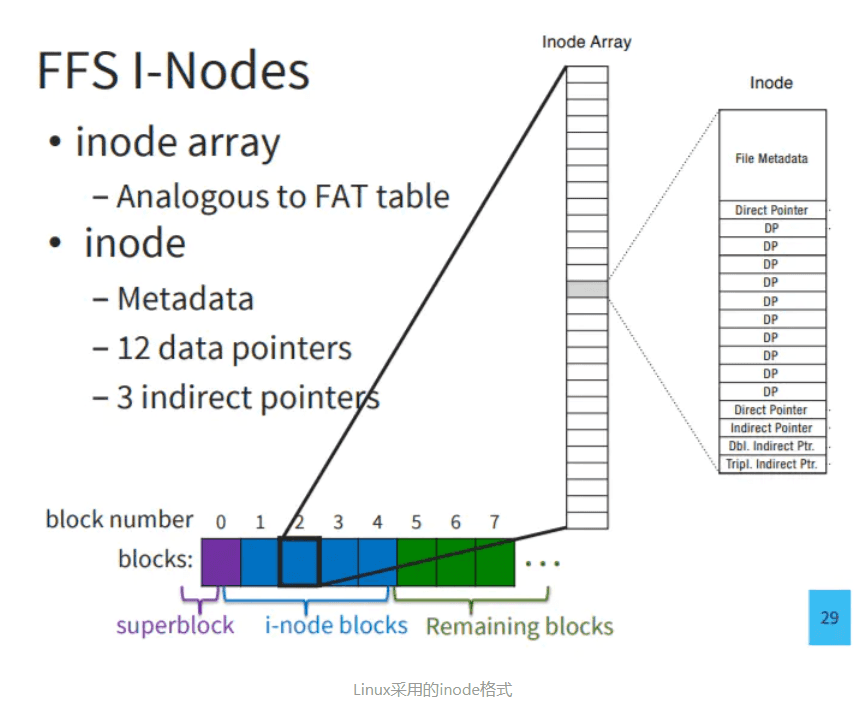
**I-Node:**Linux 文件系统的思想是把所有与数据本身无关的data(如类型,大小,owner,创建修改时间等)都存进一个特殊的block中(inode),然后通过这个block可以找到与数据相关的所有block
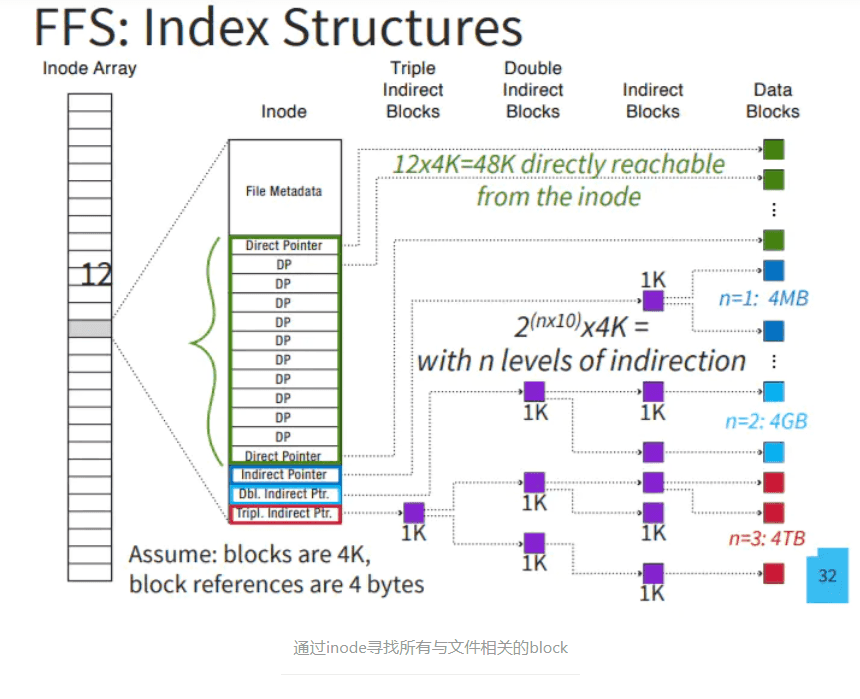
可以看到,每个inode都有12个直接block指针,假设每个block是4k,那么有48k的地址可以通过一次寻址直接找到,这对小文件的寻址速度有非常大的帮助,而文件系统中,绝大多数文件都是小文件,这样也就直接提高了文件系统的性能。如果有大文件,可以通过二次甚至三次间接寻址的方式来获取block地址,目的是能节省inode占用的空间,把更多的空间留给数据。

这里有一个比较清晰地例子表明,文件系统是如何将path转变为真正的block地址的。简而言之,inode树组成了目录树,通过树形查找获取磁盘信息。
- 【原文出处】https://www.jianshu.com/p/a5d783643fc2
- 【linux内核对IO体系的实现】https://zhuanlan.zhihu.com/p/96391501
系统调用
系统调用是操作系统提供给用户态程序使用操作系统功能的接口,是在有操作系统的情况下访问硬件资源或内核的----唯一入口—。
实现方式:
《linux下用户态程序使用系统调用》
1.高级语言如c/c++,通过使用封装好的c库(lib)函数,通常一个标准函数会使用一个或多个系统调用来实现
例如:printf --》 write系统调用
scanf --》 read系统调用
2.汇编语言,则是直接跟内核通信。内核中系统调用是通过中断机制来实现的,操作系统通过自定义内存中的中断向量表,将中断向量指向内核中的中断处理例程(程序)。而系统调用的中断在汇编中是用(int 80h)指令来实现的,
参考
http://blog.sina.com.cn/s/blog_51e9c0ab010099ow.html 系统调用
文件I/O
/*
linux中文件的内涵很多,
内核将加载到内存中的文件称为文件描述符,文件有很多种:普通文件,pipe(管道),fifo,终端。。。
进程通过使用文件描述符来使用内存中的文件对象。通常加载文件使用open系统调用来完成。
使用文件描述符的I/O函数是无缓冲,以字节为单位进行读写的。而标准io设置了缓冲区,读写单位可以是行(以换行符结尾)
全文(通过malloc分配文件大小的内存)。
文件描述符fd—>文件表项—>i节点表项
/
int open(const char filename, int flags, …)
filename:要打开的文件名
flags: 设置文件的操作方式(只读,只写,读写)
进程
操作进程环境表
#include<stdlib.h>
//每一个进程都会在栈段的上部存放一些系统的相关信息(环境表)
//获取name对应的value
char *getenv(const char *name)//cg=value
//将name=value字符串放入环境表
int putenv(char *str)//cg=0
//将name设置为value.
int setenv(char *name, char *value, int rewrite)//cg=0
int unsetenv(const char *name)//cg=0
进程创建与退出
#include<unistd.h>
pid_t fork(void);//cg:father=pid,son=0
#include<stdlib.h>
void exit(int status);//执行清理工作(执行终止处理程序,关闭标准IO),然后陷入内核
void _Exit(int status);//status:进程终止状态
//进程注册终止处理函数
int atexit(void (*func)(void));//cg=0
#include<unistd.h>
void _exit(int status);
执行新程序
#include<unistd.h>
//区别:1.前四个使用路径名,后两个使用文件名 2.参数arg传递方式l(代表list=独立参数),v(代表vector=指针数组)
int execl(const char *pathname, const char *arg0, ...);
int execv(const char *pathname, const char *arg[]);
int execle(const char *pathname, const char *arg0, ...);
int execve(const char *pathname, const char *arg[], char *const envp[]);
int execlp(const char *filename, const char *arg0, ...);
int execvp(const char *filename, const char *arg[]);
获得进程终止状态
#include<sys/wait.h>
pid_t wait(int *statloc);
pid_t waitpid(pid_t pid, int *statloc, int opt);
int waitid(idtype_t idtype, id_t id, siginfo *infop, int opt);//cg=0
pid_t wait3(int *statloc, struct rusage *rusage);
pid_t wait4(pid_t pid, int *statloc, int opt, struct rusage *ruage);
进程间通信(IPC)
pipe(管道)
fifo(命名管道)
消息队列
信号量
共享存储
套接字
XSI ipc(标识符用于进程中,键key可用于不同进程中标识同一个内核ipc结构)
消息队列
#include<sys/msg.h>
int msgget(key_t key, int flag);//cg=队列标识符
//cmd对队列要执行的操作(IPC_STAT,IPC_SET,IPC_RMID)分别取buf,设置buf,移除buf
int msgctl(int msgid, int cmd, struct msgid_ds *buf);//cg=0
//ptr代表消息,nbytes消息大小,flag可以设置为非阻塞发送消息到队列
int msgsend(int msgid, const void *ptr, size_t nbytes, int flag);//cg=0
//type代表取消息的方式,flag可以设置为MSG_NOERROR
int msgrecv(int msgid, const void *ptr, size_t nbytes, long type, int flag);
信号量
#include<sys/sem.h>
//linux上是信号量集合,因此需要一个参数nsems指定集合大小
int semget(key_t key, int nsems, int flag);//cg=信号量标识符
int semctl(int semid, int nsems, int cmd, ...);//cg=0
int semop(int semid, struct sembuf semoparray[], size_t nops);//cg=0
共享存储
#include<sys/shm.h>
int shmget(key_t key, size_t size, int flag);//cg=共享存储id
int shmctl(int shmid, int cmd, struct shmid_ds *buf);//cg=0
void *shmat(int shmid, const void *addr, int flag);//cg=共享存储的地址
int shmdt(void *addr);//cg=0
shm共享内存和内存映射mmap
shm_open
mmap
munmap
shm_unlink
ftruncate
套接字
套接字是一种进程间通信的形式,如同管道,fifo,信号量,共享存储等。套接字可以在不同通信范围(domain)内的进程之间通信,而套接字就是一个传输中介。

创建于销毁
#include<sys/socket.h>
//domain确定通信范围(AF_INET,AF_INET6,AF_UNIX,AF_UNSPEC),间接影响了地址格式
//type确定套接字类型(SOCK_STREAM,SOCK_DGRAM,SOCK_RAW,SOCK_SEQPACKET)
int socket(int domain, int type, int protocol);//cg=描述符
//how关闭套接字:SHUT_RD(关闭读取),SHUT_WR(关闭写入),SHUT_RDWR(关闭读写)
int shutdown(int socket, int how);//cg=0
设置套接字选项
#include<sys/socket.h>
//option代表要设置套接字的功能选项,level代表选项所修改的协议。
int setsockopt(int sockfd, int level, int option, const void *val, socklen_t len);//cg=0
int getsockopt(int sockfd, int level, int option, const void *val, socklen_t len);//cg=0
地址格式
//地址格式:(地址格式,在不同的通信域中是不一样的。但为了使用同一套接口,不同地址可以转换成统一的地址:sockaddr)
#include<netinet/in.h>
AF_INET域:
sockaddr_in
{
sin_family; //地址族
sin_port; //端口
struct in_addr sin_addr; //ipv4地址
}
in_addr
{
s_addr; //ipv4地址
}
#include<sys/socket.h>
客户端:
//创建socket
int connect(int sockfd, const struct sockaddr*addr, socklen_t len)//cg=0
服务器:
//socket绑定网卡
int bind(int sockfd, const struct sockaddr* addr, socklen_t len)//cg=0
int listen(int sockfd, int backlog)//cg=0
int accept(int sockfd, struct sockaddr*addr, socklen_t* len)//cg=clientfd
共用:
//关闭socket
int socket(int domain,int type,int protocol)//cg=socketfd
int shutdown(int sockfd,int how)//cg=0
int close(int sockfd)//cg=0
//数据传输
ssize_t send(int sockfd,const void*buf, size_t nbytes, int flags);
ssize_t recv(int sockfd, void* buf, size_t nbytes, int flags);
read(),write()
//设置套接字选项
int setsockopt(int sockfd, int level, int option, const void* val, socklen_t len)//cg=0
线程
创建与销毁
#include<pthread.h>
int pthread_equal(pthread_t t1, pthread_t t2);//不等0,相等=0
pthread_t pthread_self(void); //线程id
int pthread_create(pthread_t *tid, pthread_attr_t *attr/线程属性/, void*(*func)(void*)/调用函数/, void*arg/函数参数/)//cg=0
//线程退出的三种方式1.正常退出 2.被其他线程取消pthread_cancel,pthread_exit(PTHREAD_CANCELED) 3.调用pthread_exit
void pthread_exit(void\*ptr);//线程退出
int pthread_cancel(pthread_t t);//cg=0//只是提出取消请求,具体是否取消可以在线程中设置
int pthread_join(pthread_t t, void\*\*ptr)//cg=0
线程同步
- 互斥量(pthread_mutex_t)
//初始化方法有两种1.pthread_mutex_t = PTHREAD_MUTEX_INITIALIZER; 2.使用下面的init方法。
int pthread_mutex_init(pthread_mutex_t *mutex, const pthread_mutexattr_t*attr);//cg=0
int pthread_mutex_destroy(pthread_mutex_t \*mutex);//cg=0
//互斥量加锁和解锁方法
int pthread_mutex_lock(pthread_mutex_t *mutex);//cg=0
int pthread_mutex_unlock(pthread_mutex_t *mutex);//cg=0
int pthread_mutex_trylock(pthread_mutex_t*mutex);//cg=0
- 读写锁(pthread_rwlock_t)
//初始化方法
int pthread_rwlock_init(pthread_rwlock_t *rwlock, const pthread_rwlockattr_t*attr);
int pthread_rwlock_destroy(pthread_rwlock_t *rwlock);
//读写锁,两种加锁方式和一种解锁方式//cg=0
int pthread_rwlock_rdlock(pthread_rwlock_t*rwlock);
int pthread_rwlock_wrlock(pthread_rwlock_t*rwlock);
int pthread_rwlock_unlock(pthread_rwlock_t*rwlock);
- 条件变量(pthread_cond_t)
//初始化方法有两种1.pthread_cond_t = PTHREAD_COND_INITIALIZER 2.使用下面的方法
int pthread_cond_init(pthread_cond_t *cond, pthread_condattr_t* attr);//cg=0
int pthread_cond_destroy(pthread_cond_t *cond);//cg=0
//等待条件发生
int pthread_cond_wait(pthread_cond_t*cond, pthread_mutex_t *mutex);//cg=0
int pthread_cond_timewait(pthread_cond_t*cond,pthread_mutex*mutex,const timespec*timeout);//cg=0
问题
如何设计一个操作系统
从用户的角度来看,操作系统的核心是由抽象概念和其上的基本操作所构成的,而基本操作则可通过系统调用加以利用
- 定义抽象概念(–进程抽象【cpu】、虚拟地址空间抽象【内存】、文件和目录抽象【硬盘】、IO抽象【键盘鼠标。。。】、)
- 提供基本操作(向上,对开发人员)
- 确保隔离
- 管理硬件(对下,屏蔽硬件差异)
进程有关的信息存放在:地址空间中、内核的进程表
地址空间:指令,数据,堆(储物间),栈(垃圾桶),外部数据源(文件,socket)
C++服务器设计(一):基于I/O复用的Reactor模式
•阻塞式IO 阻塞于read()
•非阻塞IO 立即返回错误码(进程对多个套接字轮寻)
•上两种+多线程 线程切换开销大
•IO复用 调用epoll
•异步IO (内核将就绪的描述符,准备好并通知进程来取用。显然这样就解放了进程,将复杂任务交给内核来完成)
•reactor模式 基于事件触发机制。将需要判断的描述符注册入reactor中,然后由reactor调用事件关联处理函数。
reactor:
描述符fd --事件
事件分用器 --epoll/poll/select
事件处理器 --将处理器中的回调函数声明为虚函数,便于具体的处理器继承和实现
reactor管理器 --包含事件分用器
虚拟地址空间vs虚拟内存
- 虚拟内存=硬盘上的一块空间,当作内存看待。通过缺页中断来调入内存,通过页面替换算法调出内存
- 虚拟地址空间 = 32位系统上,每一个进程有4GB的虚拟地址空间(虚拟的可用的空间)。当cpu寄存器CR0的31位分页标志位置为1时,cpu启用MMU机构(地址转换机构),读入虚拟地址,然后根据该进程在内核中对应的页目录和页表,将该进程的虚拟地址转换为实际的物理地址。
{
★ 每一个程序自以为自己真有4GB的空间。
★ 每一个进程都有在内核区会有一个页表和页目录
} - 可重定向文件(relocatable):编译器编译而成的.o文件,可以重新定向组合成可执行文件也称之为目标文件
- 可执行文件(executable):操作系统能够直接运行的文件
- 共享库(shared object):在程序运行过程中被动态链接的文件,可以减小可执行文件的大小
- 其中可执行文件和共享库文件都是由目标文件(.o文件)构成的,因此他们的文件格式和目标文件的格式是一样的,在linux上目标文件的格式称之为(elf)文件格式
水平触发vs边缘触发
参考:
[epoll水平触发和边缘触发]https://www.jianshu.com/p/7eaa0224d797
-
读缓冲区刚开始是空的
-
读缓冲区写入2KB数据
-
水平触发(LT)和边缘触发模式(ET)此时都会发出可读信号
-
收到信号通知后,读取了1kb的数据,读缓冲区还剩余1KB数据
-
水平触发会再次进行通知,而边缘触发不会再进行通知,所以边缘触发需要一次性的把缓冲区的数据读完为止,也就是一直读,直到读到EGAIN为止,EGAIN说明缓冲区已经空了,因为这一点,边缘触发需要设置文件句柄为非阻塞
//水平触发 ret = read(fd, buf, sizeof(buf)); //边缘触发 while(true) { ret = read(fd, buf, sizeof(buf); if (ret == EAGAIN) break; }
区别:水平触发是只要读缓冲区有数据,就会一直触发可读信号,而边缘触发仅仅在空变为非空的时候通知一次.